Ryan Skraba

Dive into Avro
Who are we?
What is Avro?

Serializing data with Avro

PART I
The Schema

{
"type" : "record",
"name" : "Sensor",
"namespace" : "iot",
"fields" : [
{"name" : "id", "type" : "string"},
{"name" : "start_ms", "type" : "long"},
{"name" : "defects", "type" : "int"},
{"name" : "deviation", "type" : "float"},
{"name" : "subsensors",
"type" : {"type" : "array",
"items" : "Sensor"}}
]
}Serializing the primitives




Floating point versus integers


Gotcha: Determinism
Q: Does
serialize(42)always equalserialize(42)?A: Usually, but…

⚠️ Attention when using serialized bytes as keys in big data!
UNIONs and NULLs
{
"type" : "record",
"name" : "Sensor",
"namespace" : "iot",
"fields" : [
{"name" : "id", "type" : "string"},
{"name" : "start_ms", "type" : "long"},
{"name" : "defects", "type" : "int"},
{"name" : "deviation",
"type" : ["null", "float"]},
{"name" : "subsensors",
"type" : {"type" : "array",
"items" : "Sensor"}}
]
}
All the types
# Eight primitives
"null"
"boolean"
"int", "long"
"float", "double"
"bytes"
"string"
# Two collections
{"type", "array", "item": "iot.Sensor"}
{"type", "map", "item": "iot.Sensor"}
# Three named
{"type", "fixed", "name": "F2",
"size": 2}
{"type", "enum", "name": "E2",
"symbols": ["Z", "Y", "X", "W"]}
{"type", "record", "name": "iot.Sensor" ...}
# Plus unionBYTES

FIXED

Gotcha: Nondeterministic maps


⚠️ Don’t use MAPs in partition keys
Gotcha: Inherited namespaces
Gotcha: UTF-8 names
Gotcha: Defaults are unused
Parsing Canonical Form
Parsing Canonical Form
What have we learned?
PART II
Schema evolution: A new field
API V1 (aka Actual) (aka Writer)
API V2 (aka Expected) (aka Reader)

Every Sensor V2 temperature field will be read with NULL
Schema registries
Record evolution: By name
API V1 (aka Actual) (aka Writer)
API V3 Drop a field

API V4 Reorder fields

Ungotcha: Renaming

⚠️This one trick drives schema registries crazy!
Avro binary data never has names in it.
Don’t use a schema pair 😱
Stick the new name in the same position in the "writer" schema.
Let us never speak of this again.
Schema evolution: Primitives
Schema evolution: other types
Schema evolution: Unions
Avro message format

0xC301+ 8 byte fingerprintDoesn’t specify how to store, fetch, resolve, decode…
⚠️ PCF drops evolution attributes!
Avro file format

Obj1+ metadata16 byte sync marker
Splittable
Compressable
Appendable
Built-in Logical types
Future Avro Training subjects
Part III
What Avro solved
Uses of Avro
1. Avro for Data Exchange
Most popular serialization format for Streaming Systems

Why Avro excels for this use case?
Efficient format and Schema Evolution
Alternatives to Avro for Data Exchange
Digression 1: What about in-memory exchange formats?
Apache Arrow: Memory layout format designed for language-agnostic interoperability.
Arrow2 (not Apache) can represent Avro records as Arrow records.
2. Avro as a File Format
Supported by all Big Data Frameworks and (Cloud) Data-Warehouse

Alternatives to Avro File Format
Digression 2: Columnar formats: Parquet
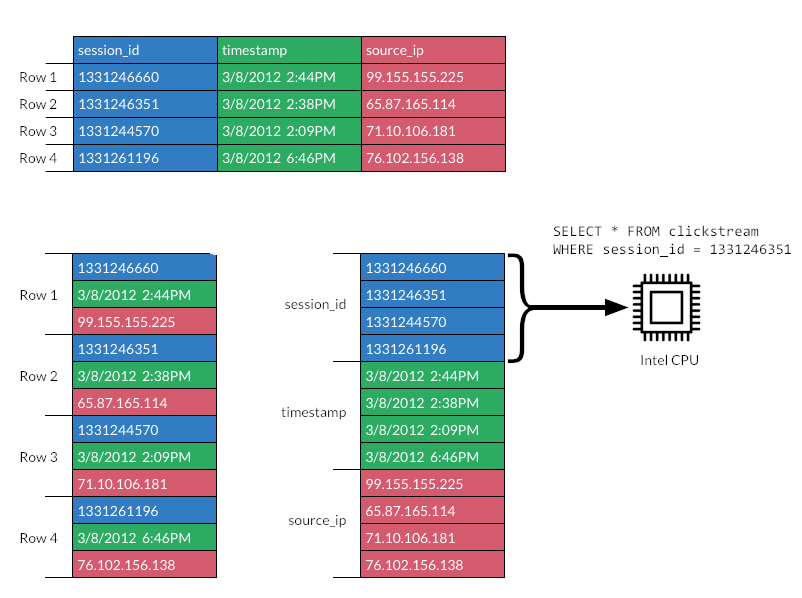
Columnar formats are better suited for analytics:
column pruning, vectorization, stats).
Digression 3: What about Table Formats?
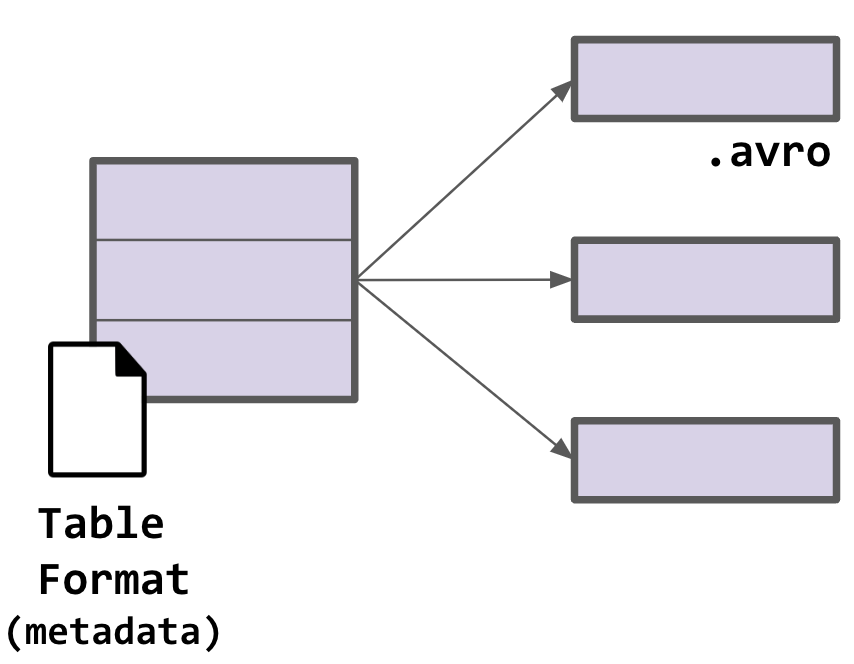
Table formats are metadata to represent all the files that compose a dataset as a “table”.
Avro can be one of those formats (i.e. Iceberg).
Advantages of Avro
State of the Project
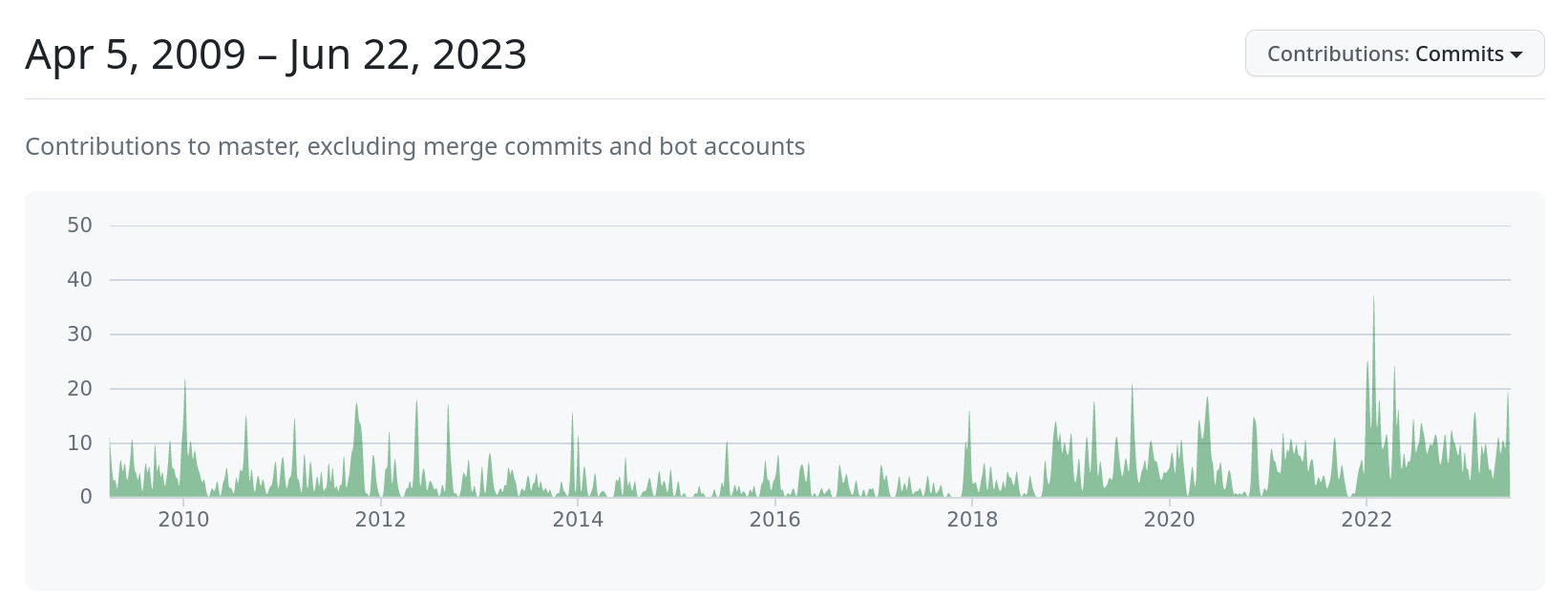
Improved Release Cadence
Improved Contributor Experience:
Github Actions, Docker, CodespacesNew Website
Rust Implementation (donated by Yelp)